1. 摘要
随着互联网技术和产业的迅速发展,接入互联网的服务器数量和网页数量也呈指数级上升。用户面临着海量的信息,传统的搜索算法只能呈现给用户(user)相同的物品(item)排序结果,无法针对不同用户的兴趣爱好提供相应的服务。为了解决信息过载(Information overload)的问题,人们提出了推荐系统。现如今,推荐系统已广泛地应用到互联网的许多方面。每天,我们阅读着新闻系统推荐的新闻,看着电影网站推荐的电影,听着音乐软件推荐的歌曲,并在电商平台上买下系统推荐的商品。个性化推荐系统的实现,大大方便了用户的使用,提升效率,也改善了用户的体验。
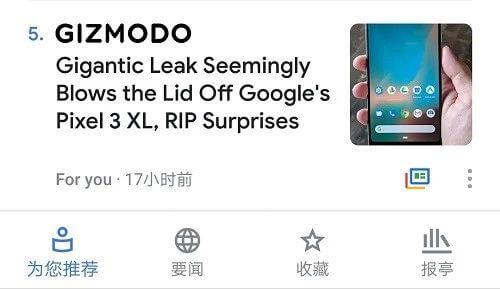
但是,用户面对着系统推荐的物品,心里可能会产生疑惑:为什么向我推荐这些内容。为了使得推荐内容更容易被用户所接受,通常在给用户推荐的同时,加上相应的解释。例如,推荐电影时加上“95%的用户观看后表示喜欢”,推荐商品时加上“根据购买记录推荐下面的商品”等等的解释。相比与传统的推荐系统,可解释系统不仅能够提升系统透明度,还能够提高用户对系统的信任和接受程度 、用户选择体验推荐产品的概率以及用户满意程度等等[^1]。
作为人工智能领域的一个重要分支,可解释推荐系统现已经应用到电子商务、医疗、学术等领域 ,推荐系统的可解释性也是一个重要的研究方向。在《Explainable Recommendation:A Survey and New Perspectives》[^2]中,作者介绍了解释生成的方法模型、可解释系统的评估以及可解释系统的发展方向。下面的内容是对文章的一个总结,并加上自己的一些理解。
2. 解释的形式
面对不同的实际应用场景,推荐系统的解释有不同的形式。
2.1 基于用户和物品的解释
基于用户和物品的推荐都是一种协同过滤推荐,根据目标用户的行为特征,发现一个兴趣相投、拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容。基于用户的解释可以表诉为“跟您相似的用户都喜欢该物品”,基于物品的解释可以表诉为“这个物品和您喜欢的其他物品相似”。
2.2 基于内容的解释
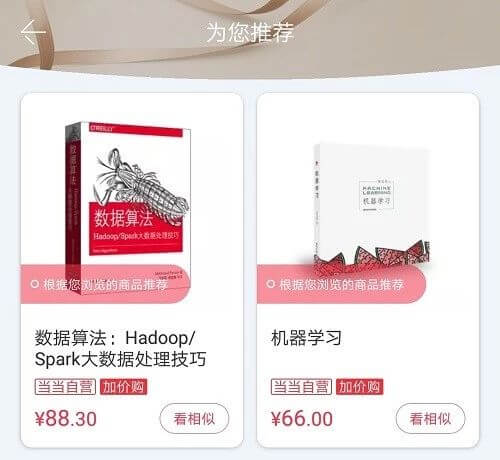
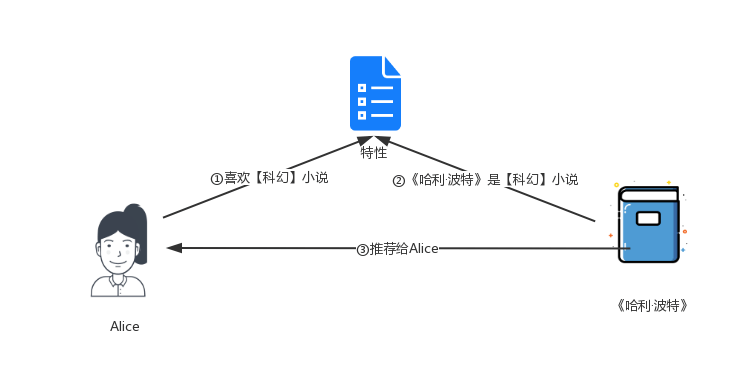
基于内容推荐解释常见的表现形式是将推荐物品中用户感兴趣的主要特征进行列举。例如,对于基于电影类型,演员,导演等生成电影推荐;基于书籍类型,价格,作者等提供书籍推荐。比如,《哈利·波特》是一本科幻小说;用户爱丽丝很喜欢科幻小说,系统就会直接推荐一本新出版的《哈利·波特》给爱丽丝。 通过以特征作为解释,用户可以直观的理解内容为什么被推荐。
2.3 文本解释
文本解释通常是生成一条文本语句作为解释。通过建立模型,分析大量的评论信息,并提取评论当中的特征及其相对应感情色彩,基于模板生成合理的评论句子作为解释。例如,“你也许对【特性】感兴趣”。系统不仅可以提供内容被推荐的解释,同时也能够提高内容不被推荐或者不适合用户的原因,这提高了推荐系统的说服力,可信度。文本解释句子也可以在没有模板的情况下生成,通过使用长期短期记忆(LSTM)生成项目的评论解释,并通过基于学习的大规模用户评论数据,模型可以自动生成合理的评论句子作为解释。
2.4 视觉解释
利用视觉图像的直观性,尝试利用产品图像进行可解释的推荐。采用与图像和文本评论信息相结合的神经注意机制来了解图像中每个区域的重要性,并将重要区域作为视觉解释进行突出显示。

2.5 社交解释
社交解释通常被应用在社交网络的朋友推荐上。在基于用户的解释中,目标用户可能根本不知道具有“相似兴趣”的用户,通过告诉用户他/她的社交朋友对推荐项目有类似兴趣,那么内容将更容易被接受。UniWalk算法就利用评级数据和社交网络来生成可解释和准确的产品推荐。
2.6 混合解释
在许多实际系统中,将多种类型的解释整合为对用户的混合解释,以使用户可以从多个角度理解推荐。系统利用多种推荐算法来构建混合推荐系统,因此,对混合推荐输出的解释一致是十分重要的。
3. 可解释推荐系统模型
目前大多数的可解释推荐方法是基于模型的方法,即推荐由矩阵/张量因子分解,分解机,主题建模和深度推荐模型等模型提供,同时,模型的推荐结果可以作为解释。
3.1 矩阵分解模型
许多可解释的推荐模型是基于矩阵分解的方法提出的,最为典型的代表有隐因子模型(LFM)和显因子模型(EFM)。
3.1.1 隐因子模型(LFM)
隐因子模型抽象出隐因子空间,其中隐因子可以理解为一个用户喜欢一个电影的隐形原因,比如电影里面有他喜欢的romantic和action元素,还有他喜欢的某个演员或者导演编剧。如果另外一个电影有类似的元素跟演员,那么他很有可能会也喜欢这部电影。LFM的核心思路就是通过评分矩阵,求出用户的向量和电影的向量[^3]。隐因子模型的特点是分类过程中,不需要关心分类的角度,结果都是基于用户打分自动聚类的,分类的粒度通过设置LFM的最终分类数来控制。
但是,隐因子模型存在着一些不足:
单一的打分不能反映用户对物品各项特征的偏好,没有利用到用户评论。
类别是抽象出来的,没有明确的含义,所以向用户推荐物品时,很难给出推荐解释。
3.1.2 显因子模型
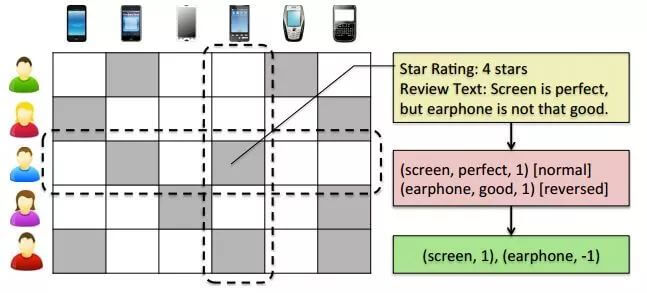
为了避免隐因子的一些问题,研究者提出了显因子模型,其基本思想是推荐在用户关心的功能上表现良好的产品[^4]。 通过对用户评论进行phrase-level(短语级)的情感分析,显式地抽取物品的特征和用户的意见。 例如下图,从用户评论中抽取物品的特性:screen、earphone。然后,抽取用户对这些特征的意见:perfect、good。如果这些表示意见是积极的情感,则用1表示;反之则用-1表示。所以在下面的例子中,情感短语表示为(screen, perfect, 1), (earphone, good, 1)这样的三元组,这一条条短语就组成了情感词典。 通过构建用户打分矩阵、用户-特征关注矩阵以及物品-特征质量矩阵,估计损失值,最后生成Top-K推荐,并可根据特征向用户解释推荐理由。
显因子模型主要的优点有:
- 充分利用用户评论,提高算法的精准度。
- 直观地解释推荐理由,从而帮助用户更快决定是否购买。特别是建议用户不要购买某些物品,有助于提高用户对系统的信任度。
另外,也有研究者将此模型拓展到张量均匀化,构建用户-项目-特征立方体,通过成对学习精选排序以确定用户对特征和项目的偏好,这有助于缓解矩阵稀疏性的问题。
3.1.3 其他
有研究者提出了情感效用逻辑模型(SULM),通过从评论中提取用户对物品特征的情感,并将这些特征和情感被整合到矩阵分解模型中,适应未知的情绪和评级,最终用于生成建议。所提出的方法不仅向用户提供推荐的项目,而且还提供项目的推荐特征,并且这些特征用作推荐的解释。
另外研究人员还研究了基于模型的用户和/或基于项目的解释方法,这些方法可以仅根据用户项目评级矩阵提供可解释的建议。也有科学家提出提出可解释的受限Boltzmann机器用于协同过滤和推荐,该方法可提供基于用户的邻域样式解释。
3.2 主题模型
主题模型是对文字隐含主题进行建模的方法。例如,判断两篇文档是否相关往往不只决定于字面上的词语重复,还取决于文字背后的语义关联。对语义关联的挖掘,可以让我们的搜索更加智能化。而主题模型则是用于解决这个方法的非常经典的模型。 它克服了传统信息检索中文档相似度计算方法的缺点,并且能够在海量互联网数据中自动寻找出文字间的语义主题。
研究者们首先提出隐藏因子和主题(HFT)模型,通过将项目(或用户)潜在向量的每个维度相关联,将潜在因子模型和潜在Dirichlet分配(LDA)联系起来,提高评级预测的准确性。随后,有研究者提出提出了FLAME模型(Factorized Latent Aspect ModEl),它结合了协同过滤和基于方面的意见挖掘的优点。从过去的评论中了解用户对不同方面的个性化偏好,并通过集体智慧预测用户对新项目的评估。
3.3 深度学习模型
深度学习和表征学习在推荐研究界引起了很多关注,并且它们被广泛应用于可解释的推荐上。到目前为止,相关的可解释推荐模型涵盖了广泛的深度学习技术,包括卷积神经网络(CNN),循环神经网络RNN / 长短期记忆网络(LSTM),注意力机制,记忆网络等,它们被应用于关于可解释性的各种推荐任务,例如top-n推荐, 顺序推荐等。
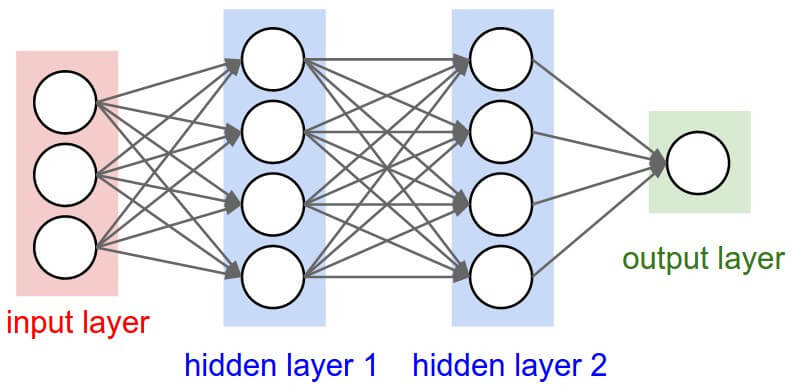
有研究者使用卷积神经网络(CNN),对具有双重局部和全局关注的文本评论来模拟用户偏好和物品属性,突出显示评论中的相关单词作为解释,以帮助用户理解建议。另外也有研究者引入了注意机制来探索评论的有用性,并提出了一种神经注意回归模型,其中包含了复习水平的解释推荐。最近,基于自然语言生成的可解释建议已经应用于商业电子商务系统。例如,淘宝的推荐系统根据数据对序列的自然语言生成推荐项目解释。
3.4 知识图谱
知识图谱最初由谷歌公司于2012年5月16日宣布推出,旨在提升搜索引擎返回的答案质量和用户查询的效率 。有知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更大可能地满足用户的查询需求[^5]。
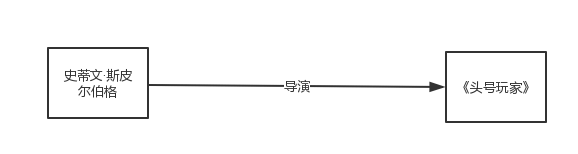
在各种辅助信息中,知识图谱作为一种新兴类型的辅助信息近几年逐渐引起了研究人员的关注。知识图谱(knowledge graph)是一种语义网络,其结点(node)代表实体(entity)或者概念(concept),边(edge)代表实体/概念之间的各种语义关系(relation)。[^6]一个知识图谱由若干个三元组(h、r、t)组成,其中h和t代表一条关系的头结点和尾节点,r代表关系。例如下图所示的关系,表达了斯蒂文·斯皮尔伯格导演了头号玩家电影,其中h=斯蒂文·斯皮尔伯格、t=头号玩家、r=导演。
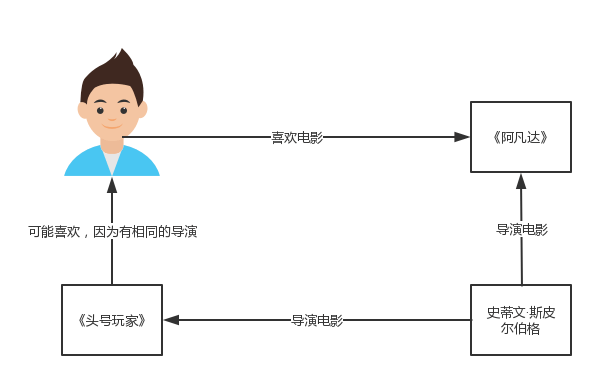
通过组合若干个语义关系,可以生成知识图谱。知识图谱中包含了实体之间丰富的语义关联,可为推荐系统提供了潜在的辅助信息来源。和其他的推荐模型相比,知识图谱的引入可以让推荐系统有如下特性:
- 精确性。知识图谱为物品引入了更多的语义关系,可以深层次地发现用户兴趣。
- 多样性。知识图谱提供了不同的关系连接种类,有利于推荐结果的发散。
- 可解释性 。知识图谱可以连接用户的历史记录和推荐结果,从而提高用户对推荐结果的满意度和接受度,增强用户对推荐系统的信任。
但是,知识基于路径的知识图谱推荐方法存在一定的局限性,研究者提出了Ripple Network。这是一个将知识图纳入推荐系统的端到端框架,类似于在水面上传播的实际波纹,通过自动迭代,沿知识图中的链接扩展用户的潜在兴趣,并可以在知识图上找到推荐项路径来提供解释。
3.5 数据挖掘
数据挖掘方法对于推荐研究很重要,数据挖掘方法通常具有可解释推荐的特别优势,因为它们可以生成非常直接的解释,并且这些解释易于用户理解。一个典型的例子就是“沃尔玛啤酒和尿布”的故事。
现如今,很多的互联网平台,包括电商、视频、打车等平台在内,都会使用数据挖掘的方式对用户进行商品的推荐,用户每天浏览消费,产生海量的数据供平台分析。平台通过分析数据,可以直观的告知用户当前的流行趋势、地区特色等等,并以此为解释将物品推荐给用户。
作者还在文中提到Youtube视频推荐系统,推荐系统是通过网站上用户监视活动的会话,为每个用户设置视频的种子集,其中包括用历史、收藏、喜欢、评级等等视频,将这些种子视频的相关视频作为推荐候选项目,并将关联规则作为解释。虽然现在(2018年)Youtube的视频推荐是不提供推荐解释,但是推荐到内容却是如此的精准,这是因为Google在2016年开始采用了深度学习算法,包括Google Assistant、Google Map、Google Photos等等谷歌产品。尤其是在今年2018的Google I/O大会上,Google的AI技惊四座,将AI又推向新的热潮。
4. 可解释推荐系统的评估
中国有句谚语:鱼和熊掌不可兼得,这似乎一直是一个历史难题。人们在想要得到某一些东西的时候,往往需要失去另一些东西。在算法领域,为了设计出一个时间效率高的算法,通常会舍弃一些空间,这是所谓的空间换时间。同样的,在推荐领域,为了使得推荐性能更好,不得不在可解释性上做出让步。因此,可解释的推荐算法的评估主要在评级预测或top-n推荐方面,以及评估说服性和有效性等方面的解释性能。下面就推荐性能以及推荐解释性的评估方法做出总结。

4.1 推荐性能评估
推荐性能的评估方法分为离线评估和在线评估。在离线方法中,通常可以使用平均绝对误差(MAE)和均方根误差(RMSE)来评估评级预测的性能。对于top-n推荐,可以使用许多排名度量进行评估。 最常用的度量可以是精确度,召回率,F1度量值,归一化折扣累积增益量(NDCG)等。在在线方法中,通过点击率(CTR),转换率(CR)以及其他与业务相关的衡量指标进行评估。在线评估通常被商业公司使用,可以通过大量用户的访问进行实验。
4.2 解释性能评估
解释性能评估的方法中也包含在线评估和离线评估,另外还包括用户研究和案例研究评估。通常,在线评估更容易实施,而在线评估和用户研究取决于实际系统中数据和用户的可用性。
4.2.1 离线评估
离线评估通常有两种评估推荐解释的方法。一种是忽略解释质量,评估可解释推荐模型可以解释的推荐项目的百分比;第二种方法是准确评估解释的质量。但是,为了更全面地评估建议解释,需要更多的离线评估措施和协议。
4.2.2 在线评估
评估解释建议的另一种方法是通过在线实验,也是基于转换率(CR)和点击率(CTR)等在线测量,类似于推荐性能的在线评估。可能有几种不同的观点需要考虑在线评估解释,包括说服力,有效性,效率和解释的满意度。
4.2.3 基于用户研究的模拟在线评估
在线评估需要一个拥有大量用户的已部署系统,这通常需要广泛的协作或与商业公司合作。一种较为简单的方式是通过基于志愿者或付费实验科目的用户研究,模拟在线评估。志愿者或有偿受试者可以直接由研究人员雇用,也可以基于各种在线众包平台聘用。
4.2.4 案例研究定性评估
作为定性分析的案例研究也经常用于可解释的推荐系统研究。提供案例研究有助于理解可解释推荐模型背后解释的有效性,并且有助于读者理解提议的方法何时起作用以及何时不起作用。研究者提供了解释顺序的案例研究,作者发现许多顺序建议都可以根据用户的“一对多”或“一对一”行为模式进行解释,这些解释可以帮助用户清楚地理解为什么推荐一个项目,以及推荐的方式。
5. 可解释推荐系统的应用
可解释推荐的研究和应用跨越了许多不同的场景,例如可解释的电子商务推荐,可解释的社交推荐,可解释的多媒体推荐等,甚至在医疗、学术等领域 ,也已经开始应用。
可解释推荐系统在电子商务产品的推荐中被广泛采用,平台通过商品的推荐可以提供个性化服务,提高用户信任度和粘性。当然,还可以增加营收。 例如,亚马逊每年35%的销售额都来源于它的推荐。在社交领域中,好友的推荐、新闻推送推荐以及以及社交环境中的博客,新闻,音乐,旅行计划,网页,图像,标签等的推荐。社交关系不经能够提高推荐性能,还可以提高推荐的解释能力。可解释性推荐对许多其他应用场景也很重要,例如学术推荐,引用推荐,医疗保健推荐等。虽然关于这些主题的直接可解释推荐工作仍然有限,但研究人员已开始考虑可解释性问题在这些系统中。
6. 新的研究方向
长期以来,推荐系统主要集中在开发广泛的模型,以尽可能有效地找到最相关的结果。然而,推荐模型的可解释性却被忽视了。缺乏可解释性主要存在于两个方面:
- 推荐系统的输出(即推荐结果)难以向系统用户解释。
- 推荐模型的机制(即推荐算法)对系统设计师来说难以解释。
现如今,随着科技的不断发展,不断有新的研究成果出现,我们可以通过使用深度学习、知识增强、异构信息模型、自然语言生成等技术,来使得推荐模型生成解释。作为人工智能领域的一个研究分支,越来越多的人加入到其中的研究。期望知识图谱技术,深度学习,自然语言生成,动态建模,模型聚合和会话系统技术在可解释的推荐方面取得更多成就,可解释的推荐系统的目标也将超越说服力,以进一步使系统用户/设计者在许多其他方面受益。
[^1]: 微软亚洲研究院. 可解释推荐系统:身怀绝技,一招击中用户心理. https://zhuanlan.zhihu.com/p/29374802.
[^2]: Yongfeng Zhang and Xu Chen. Explainable Recommendation:A Survey and New Perspectives. arXiv Preprint 2018. arXiv:1804.11192.
[^3]: CSDN. LFM (Latent Factor Model) 隐因子模型 + SVD (singular value decomposition) 奇异值分解. https://blog.csdn.net/asd136912/article/details/78290679.
[^4]: Zhang Y, Lai G, Zhang M, et al. Explicit factor models for explainable recommendation based on phrase-level sentiment analysis[M]. ACM, 2014.
[^5]: Wikipedia. Knowledge Graph. https://en.wikipedia.org/wiki/Knowledge_Graph.
[^6]: 微软亚洲研究院. 推荐算法不够精准?让知识图谱来解决 https://zhuanlan.zhihu.com/p/37943501.


